创建推理服务¶
智能算力目前提供以 Triton、vLLM 作为推理框架,用户只需简单配置即可快速启动一个高性能的推理服务。
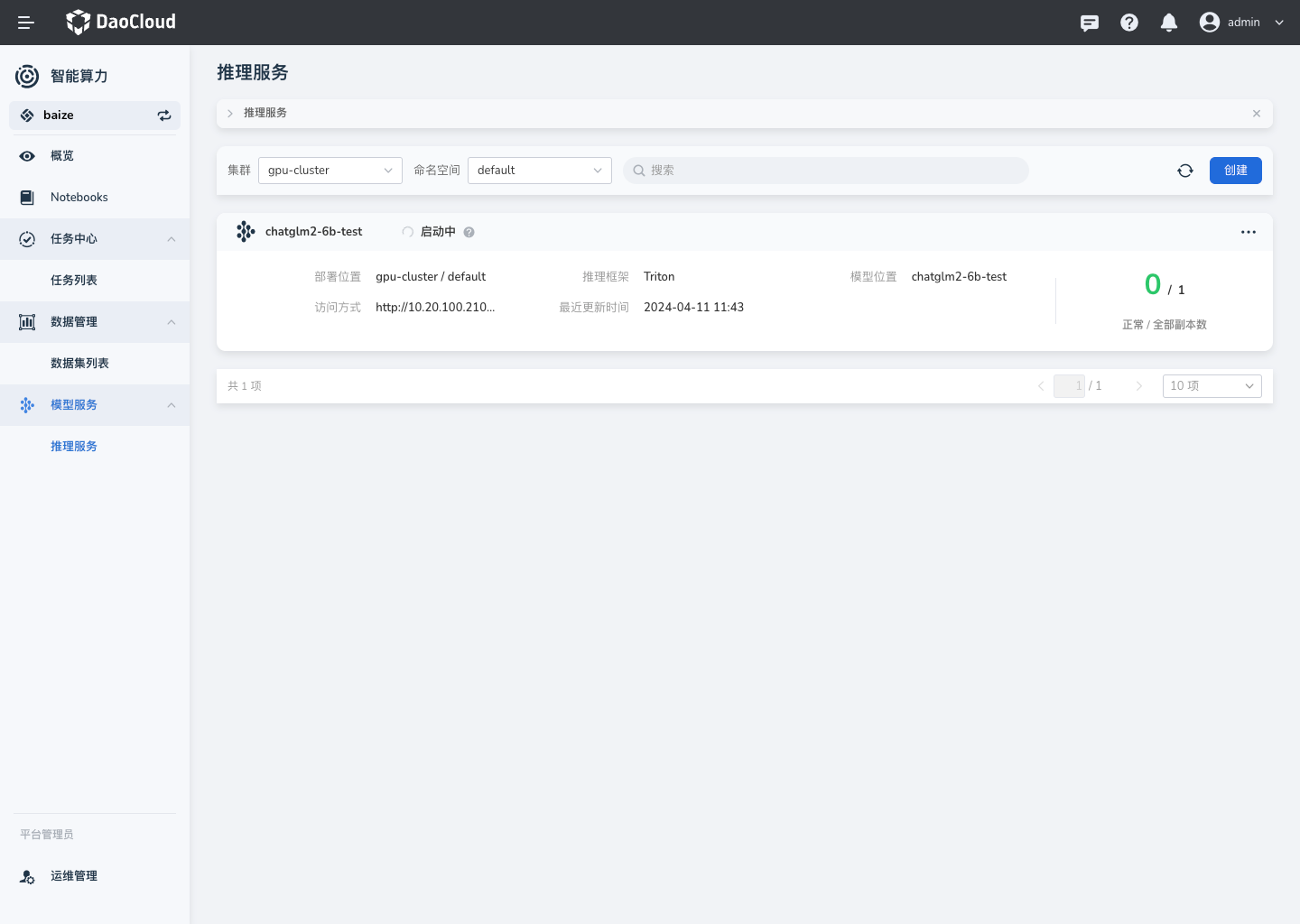
推理服务控制台¶
准备模型数据集¶
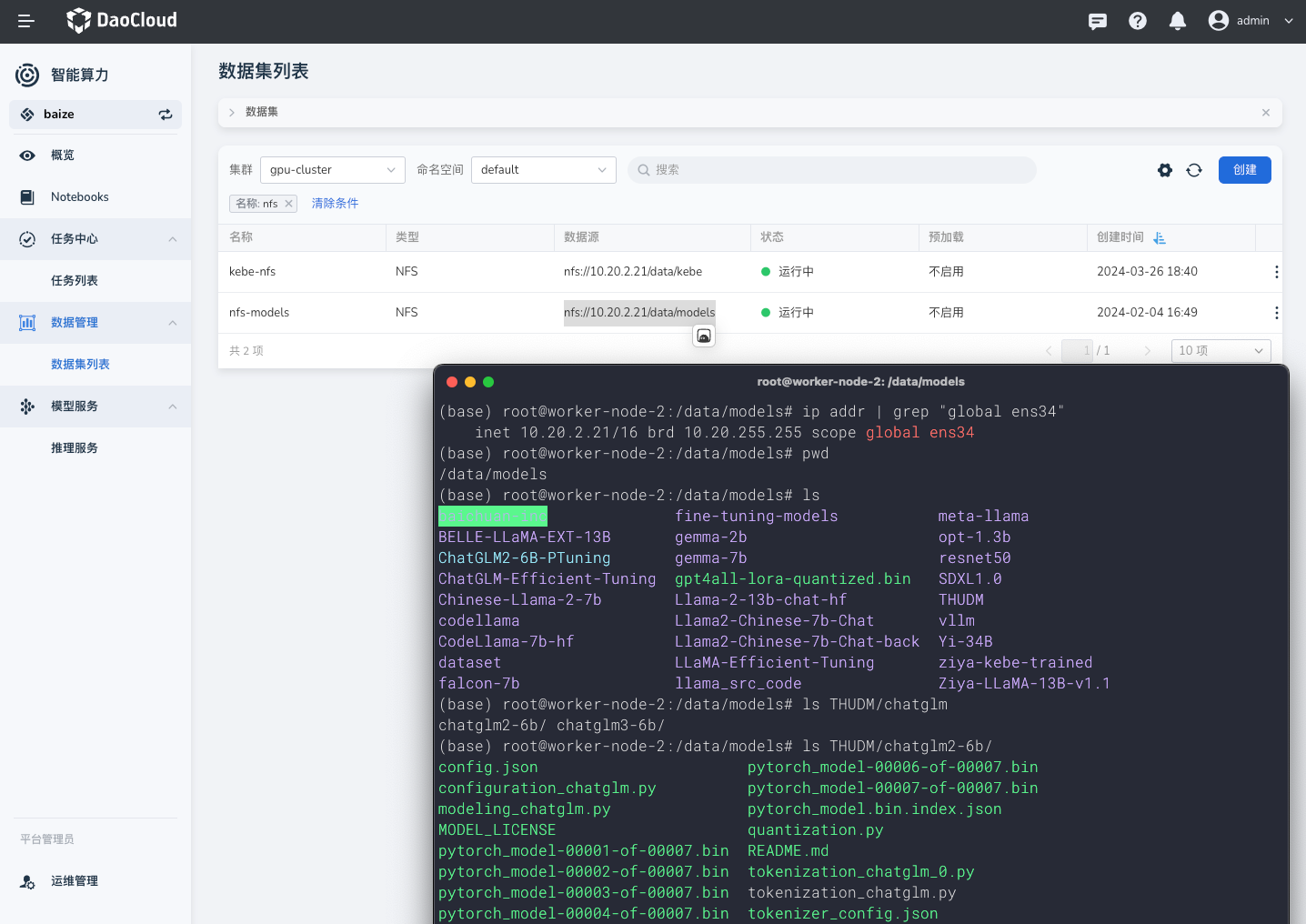
在智能算力中,我们使用数据集来进行模型文件的管理;方便您将任务训练的模型文件,直接挂载到推理服务中使用。
默认情况下,推荐使用 NFS 或者 S3 服务来存储模型文件;
当您创建成功后,我们会自动进行模型文件预热到集群本地;预热过程不会占用 GPU。
这里以
nfs为例。
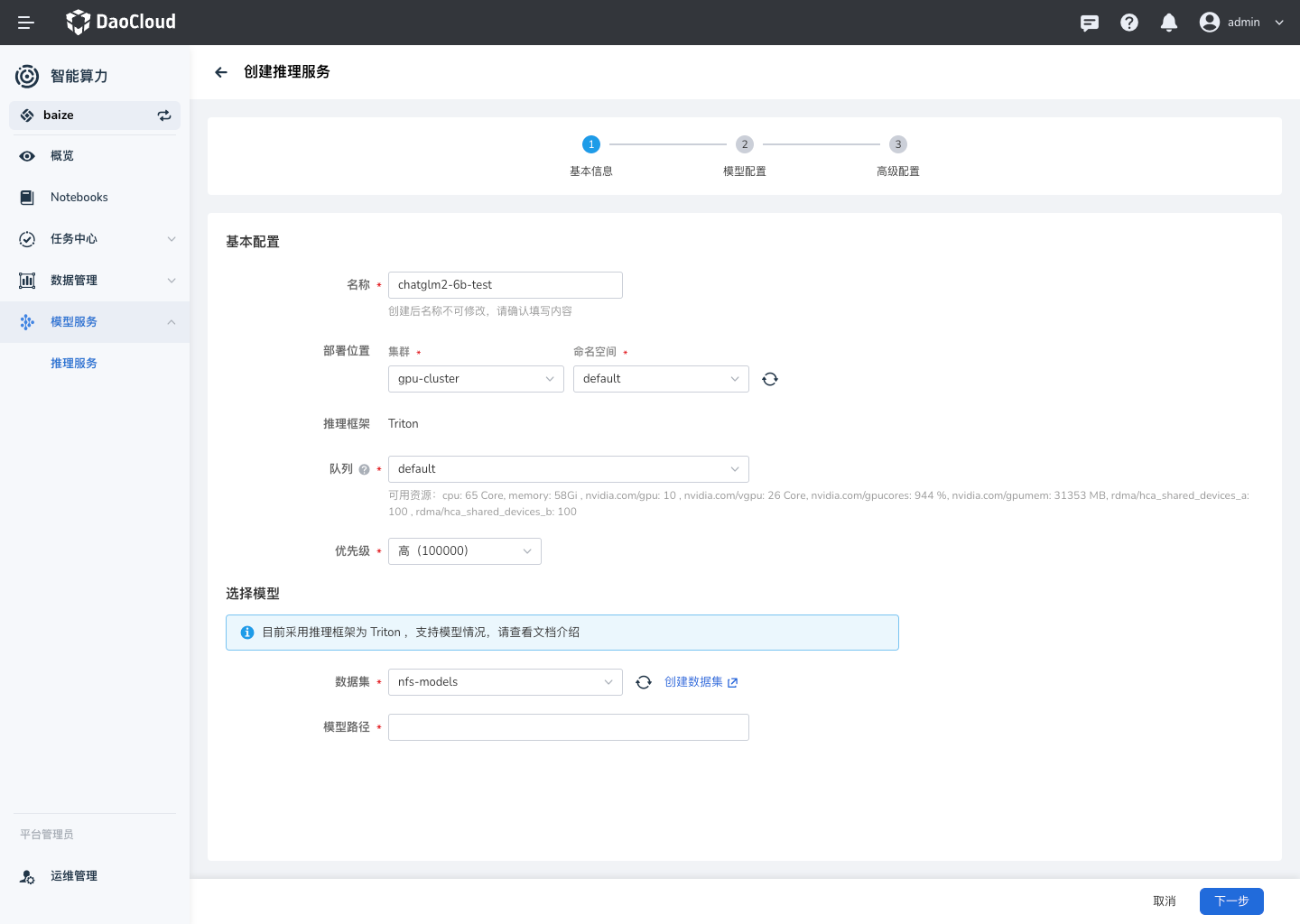
创建¶
目前已经支持表单创建,可以界面字段提示,进行服务创建。
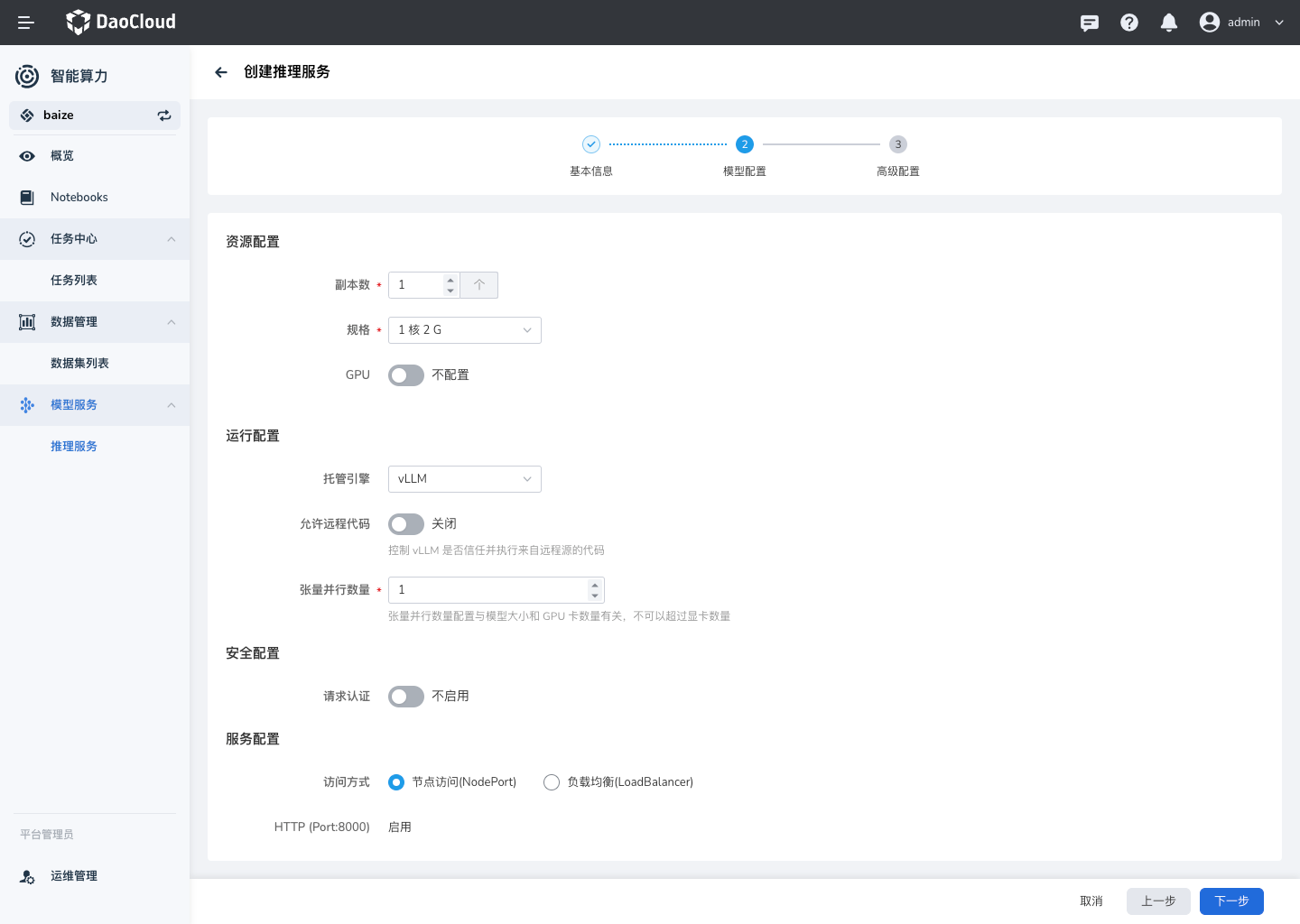
配置队列¶
配置模型路径¶
参考上图中数据集的的模型位置,这里选择如下:
- 数据集为
nfs-models模型路径为:THUDM/chatglm2-6b
模型配置¶
配置认证策略¶
支持 API key 的请求方式认证,用户可以自定义增加认证参数。
高级设置:亲和性调度¶
支持 根据 GPU 资源等节点配置实现自动化的亲和性调度,同时也方便用户自定义调度策略。
访问¶
模型推理服务默认提供了多种访问方式,以便客户端可以通过不同的协议与推理服务进行交互。您可以通过以下方式访问服务:
- HTTP/REST API:
- Triton 提供了一个基于 REST 的 API,允许客户端通过 HTTP POST 请求进行模型推理。
-
客户端可以发送 JSON 格式的请求体,其中包含输入数据和相关的元数据。
-
gRPC API:
- Triton 还提供了 gRPC 接口,它是一种高性能、开源、通用的 RPC 框架。
-
gRPC 支持流式处理,可以更有效地处理大量数据。
-
C++ 和 Python 客户端库:
- Triton 为 C++ 和 Python 提供了客户端库,使得在这些语言中编写客户端代码更加方便。
- 客户端库封装了 HTTP/REST 和 gRPC 的细节,提供了简单的函数调用来执行推理。
每种访问方式都有其特定的用例和优势。例如,HTTP/REST API 通常用于简单和跨语言的场景,而 gRPC 则适用于需要高性能和低延迟的应用。C++ 和 Python 客户端库提供了更丰富的功能和更好的性能,适合在这些语言环境中进行深度集成。
API 访问¶
HTTP 访问¶
-
发送 HTTP POST 请求:使用工具如
curl或 HTTP 客户端库(如 Python 的requests库)向 Triton Server 发送 POST 请求。 -
构建请求体:请求体通常包含要进行推理的输入数据,以及模型特定的元数据。
-
指定模型名称:在请求中指定你想要访问的模型名称
chatglm2-6b。 -
设置 HTTP 头:包含模型输入和输出的元数据。
示例 curl 命令¶
curl -X POST http://<host>:8000/v2/models/chatglm2-6b/infer \
-H 'Content-Type: application/octet-stream'
--data-binary @input_data
<host>是 Triton Inference Server 运行的主机地址。8000是 Triton 默认的 HTTP 端口,如果配置不同,请相应更改。input_data是你的模型输入数据文件。
gRPC 访问¶
-
生成客户端代码:使用 Triton 提供的模型定义文件(通常是
.pbtxt文件),生成 gRPC 客户端代码。 -
创建 gRPC 客户端实例:使用生成的代码创建 gRPC 客户端。
-
发送 gRPC 请求:构造 gRPC 请求,包含模型输入数据。
-
接收响应:等待服务器处理并接收响应。
示例 gRPC 访问代码¶
from triton_client.grpc import *
from triton_client.utils import *
# 初始化 gRPC 客户端
try:
triton_client = InferenceServerClient('localhost:8001')
except Exception as e:
logging.error("failed to create gRPC client: " + str(e))
# 构造输入数据
model_name = 'chatglm2-6b'
input_data = ... # 你的模型输入数据
# 创建输入和输出
inputs = [InferenceServerClient.Input('input_names', input_data.shape, "TYPE")]
outputs = [InferenceServerClient.Output('output_names')]
# 发送推理请求
results = triton_client.infer(model_name, inputs, outputs)
# 获取推理结果
output_data = results.as_numpy('output_names')
localhost:8001是 Triton 默认的 gRPC 端口,如果配置不同,请相应更改。input_data是你的模型输入数据,需要根据模型要求进行预处理。TYPE是模型输入的数据类型,如FP32、INT32等。
请注意,上述示例代码需要根据你的具体模型和环境进行调整,输入数据的格式和内容也需要符合模型的要求。